Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Kubernetes is a powerful orchestration platform, but sometimes pods get stuck in the ContainerCreating status. In this article, we’ll explore common reasons for this issue and provide practical solutions to get your pods up and running smoothly. If you’ve ever faced this frustrating situation, read on to discover how to troubleshoot and resolve it.
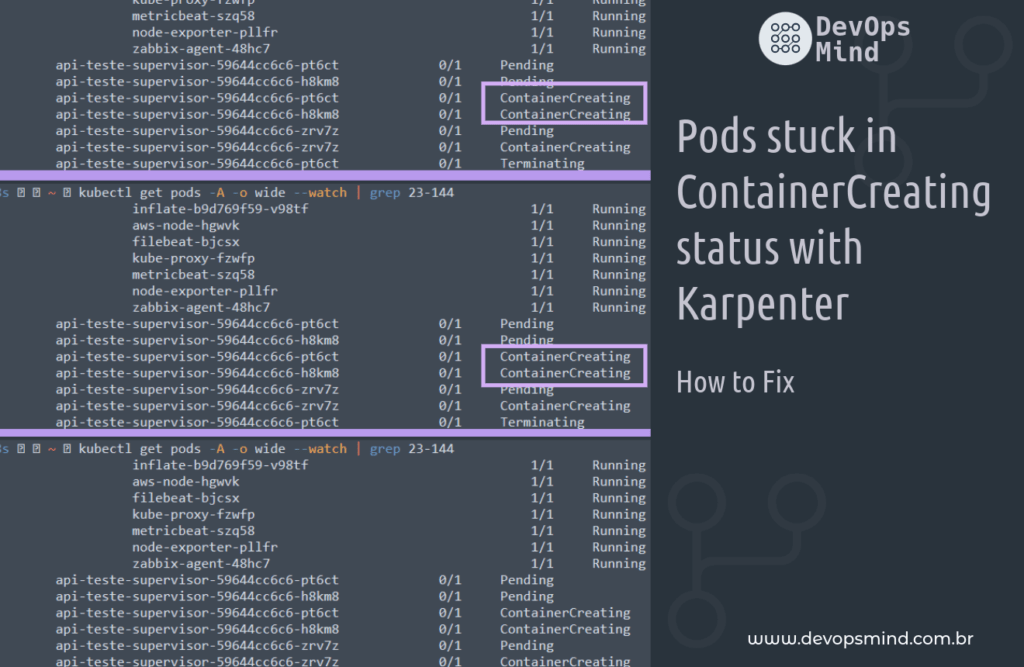
Table of contents
We face an intriguing and challenging issue: the recurring occurrence of Pods getting stuck in the “ContainerCreating” when trying to climb onto nodes provisioned through Karpenter. This phenomenon has significant impacts on the normal operation of Kubernetes, preventing the efficient deployment of containers and, consequently, affecting the agility and reliability of the environment.
During my Karpenter deployment journey, I noticed that Pods that used Docker Image based on PHP Alpine were getting stuck at “ ContainerCreating”, as per:
fernando@lab-1487 ~ kubectl get pods -A -o wide --watch | grep 23-144 1|1 ↵ 11105 16:06:39
default inflate-b9d769f59-v98tf 1/1 Running 0 25m 172.31.21.32 ip-172-31-23-144.ec2.internal <none> <none>
kube-system aws-node-hgwvk 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system filebeat-bjcsx 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system kube-proxy-fzwfp 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system metricbeat-szq58 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
lens-metrics node-exporter-pllfr 1/1 Running 0 33m 172.31.27.199 ip-172-31-23-144.ec2.internal <none> <none>
monitoring zabbix-agent-48hc7 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-h8km8 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-h8km8 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-zrv7z 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-zrv7z 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 10s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 10s <none> ip-172-31-23-144.ec2.internal <none> <none>
The Pods that had problems were random, many Pods from other projects went up correctly.
Several components of the Kubernetes Cluster were reviewed during the Troubleshooting, such as the Pod, Kubelet, Karpenter logs and other pertinent items.
In the Pods there were these logs:
Warning Failed Pod api-cep-nbtt-59644cc6c6-pt6ct spec.containers{api-cep-nbtt} kubelet, ip-172-31-23-144.ec2.internal Error: cannot find
volume "kube-api-access-8lv5h" to mount into container "api-cep-nbtt"While the Kubelet service had this information:
[root@ip-172-31-23-144 bin]# systemctl status kubelet.service
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubelet-args.conf, 30-kubelet-extra-args.conf
Active: active (running) since Thu 2023-06-22 18:33:15 UTC; 1h 24min ago
Docs: <https://github.com/kubernetes/kubernetes>
Main PID: 2949 (kubelet)
CGroup: /runtime.slice/kubelet.service
└─2949 /usr/bin/kubelet --cloud-provider aws --config /etc/kubernetes/kubelet/kubelet-config.json --kubeconfig /var/lib/kubelet/kubeconfig --container-runtime remote --container-runtime-endpoint un...
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.402350 2949 kubelet.go:1951] "SyncLoop DELETE" source="api" pods=[api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408804 2949 kubelet.go:1945] "SyncLoop REMOVE" source="api" pods=[api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408869 2949 kubelet.go:2144] "Failed to delete pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct"...d not found"
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034178 2949 kubelet_pods.go:160] "Mount cannot be satisfied for the container, because the volume is missing or the volume mounte...
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034515 2949 kuberuntime_manager.go:864] container &Container{Name:api-cep-nbtt,Image:311635504079.dkr.ecr.u...inerPort:900
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: ],},HTTPGet:nil,TCPSocket:nil,},PreStop:nil,},TerminationMessagePath:/dev/termination-log,ImagePullPolicy:IfNotPresent,SecurityContext:...lObjectRefer
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.037294 2949 pod_workers.go:190] "Error syncing pod, skipping" err="failed to \\"StartContainer\\" for \\"api-cep-nbtt\\" wi...
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.326023 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc...285179c693f}
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.337575 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc...3ee0fbe11b0}
Jun 22 19:22:33 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:33.383158 2949 kubelet_volumes.go:140] "Cleaned up orphaned pod volumes dir" podUID=33966fe3-4ceb-481d-9d57-4586953a8692...692/volumes"
Hint: Some lines were ellipsized, use -l to show in full.
Full version:
[root@ip-172-31-23-144 bin]# systemctl status kubelet.service -l
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubelet-args.conf, 30-kubelet-extra-args.conf
Active: active (running) since Thu 2023-06-22 18:33:15 UTC; 1h 28min ago
Docs: <https://github.com/kubernetes/kubernetes>
Main PID: 2949 (kubelet)
CGroup: /runtime.slice/kubelet.service
└─2949 /usr/bin/kubelet --cloud-provider aws --config /etc/kubernetes/kubelet/kubelet-config.json --kubeconfig /var/lib/kubelet/kubeconfig --container-runtime remote --container-runtime-endpoint unix:///run/containerd/containerd.sock --node-ip=172.31.23.144 --pod-infra-container-image=311401143452.dkr.ecr.us-east-1.amazonaws.com/eks/pause:3.5 --v=2 --node-labels=intent=apps,karpenter.sh/capacity-type=spot,karpenter.sh/provisioner-name=default
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.402350 2949 kubelet.go:1951] "SyncLoop DELETE" source="api" pods=[api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408804 2949 kubelet.go:1945] "SyncLoop REMOVE" source="api" pods=[api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408869 2949 kubelet.go:2144] "Failed to delete pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct" err="pod not found"
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034178 2949 kubelet_pods.go:160] "Mount cannot be satisfied for the container, because the volume is missing or the volume mounter (vol.Mounter) is nil" containerName="api-cep-nbtt" ok=false volumeMounter={Name:kube-api-access-8lv5h ReadOnly:true MountPath:/var/run/secrets/kubernetes.io/serviceaccount SubPath: MountPropagation:<nil> SubPathExpr:}
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034515 2949 kuberuntime_manager.go:864] container &Container{Name:api-cep-nbtt,Image:311635504079.dkr.ecr.us-east-1.amazonaws.com/api-apphook:supervisor-193,Command:[],Args:[],WorkingDir:,Ports:[]ContainerPort{ContainerPort{Name:9000tcp,HostPort:0,ContainerPort:9000,Protocol:TCP,HostIP:,},},Env:[]EnvVar{},Resources:ResourceRequirements{Limits:ResourceList{cpu: {{500 -3} {<nil>} 500m DecimalSI},memory: {{536870912 0} {<nil>} BinarySI},},Requests:ResourceList{cpu: {{200 -3} {<nil>} 200m DecimalSI},memory: {{268435456 0} {<nil>} BinarySI},},},VolumeMounts:[]VolumeMount{VolumeMount{Name:kube-api-access-8lv5h,ReadOnly:true,MountPath:/var/run/secrets/kubernetes.io/serviceaccount,SubPath:,MountPropagation:nil,SubPathExpr:,},},LivenessProbe:nil,ReadinessProbe:nil,Lifecycle:&Lifecycle{PostStart:&Handler{Exec:&ExecAction{Command:[/bin/bash -c touch /var/www/storage/logs/laravel.log && chgrp -R www-data /var/www/bootstrap/ /var/www/storage/ /var/www/storage/logs/ && chmod -R g+w /var/www/bootstrap/ /var/www/storage/ /var/www/storage/logs/ && tail -f /var/www/storage/logs/laravel.log > /proc/1/fd/2 &
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: ],},HTTPGet:nil,TCPSocket:nil,},PreStop:nil,},TerminationMessagePath:/dev/termination-log,ImagePullPolicy:IfNotPresent,SecurityContext:nil,Stdin:false,StdinOnce:false,TTY:false,EnvFrom:[]EnvFromSource{EnvFromSource{Prefix:,ConfigMapRef:&ConfigMapEnvSource{LocalObjectReference:LocalObjectReference{Name:api-apphook-php,},Optional:nil,},SecretRef:nil,},},TerminationMessagePolicy:File,VolumeDevices:[]VolumeDevice{},StartupProbe:nil,} start failed in pod api-cep-nbtt-59644cc6c6-pt6ct_api-cep-homolog(22966fe3-4ceb-481d-9d57-4586953a8692): CreateContainerConfigError: cannot find volume "kube-api-access-8lv5h" to mount into container "api-cep-nbtt"
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.037294 2949 pod_workers.go:190] "Error syncing pod, skipping" err="failed to \\"StartContainer\\" for \\"api-cep-nbtt\\" with CreateContainerConfigError: \\"cannot find volume \\\\\\"kube-api-access-8lv5h\\\\\\" to mount into container \\\\\\"api-cep-nbtt\\\\\\"\\"" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct" podUID=22966fe3-4ceb-481d-9d57-4586953a8692
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.326023 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-h8km8" event=&{ID:5a5e6258-6d1e-4faa-ac8c-4a0c10670eb6 Type:ContainerStarted Data:9af88fa8f99000720300c1d7f7cab91501db31b5a4ba36d51c9a0285179c693f}
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.337575 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-zrv7z" event=&{ID:eabe3711-a972-494b-922a-3ad1d5c72936 Type:ContainerStarted Data:f9cdd2dd078343c8f2fa9f4744a14d19d4a24992011c0b31ef33f3ee0fbe11b0}
Jun 22 19:22:33 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:33.383158 2949 kubelet_volumes.go:140] "Cleaned up orphaned pod volumes dir" podUID=22966fe3-4ceb-481d-9d57-4586953a8692 path="/var/lib/kubelet/pods/22966fe3-4ceb-481d-9d57-4586953a8692/volumes"
However, analyzing the logs did not come to anything conclusive.
After carrying out a lot of research and testing, the solution to avoid errors in kubernetes pod status containercreating was found:
It is necessary to modify the Container Runtime used in the Karpenter Provisioner.
From:containerd
To:dockerd

In the Provisioner settings in Karpenter, it was necessary to adjust the ContainerRuntime like this:
############### ContainerRuntime
kubeletConfiguration :
containerRuntime : dockerdAdjust Karpenter provisioner:
kubectl delete -f provisioner_v4.yaml
kubectl apply -f provisioner_v4.yamlNodes rising after adjustment:
fernando@lab-1487 ~ 11123 17:16:18
kubectl get node --selector=intent=apps -L kubernetes.io/arch -L node.kubernetes.io/instance-type -L karpenter.sh/provisioner-name -L topology.kubernetes.io/zone -L karpenter.sh/capacity-type --watch
NAME STATUS ROLES AGE VERSION ARCH INSTANCE-TYPE PROVISIONER-NAME ZONE CAPACITY-TYPE
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 2s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 20s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 50s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 78s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 80s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 110s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spotAnd now the Pods managed to climb, all of them with status in running, as expected:
fernando@lab-1487 ~ kubectl get pods -A -o wide --watch | grep 21-230 1|SIGINT(2) ↵ 11116 17:20:59
app-lab-homolog app-lab-nginx-574bf47b65-whd9l 1/1 Running 0 3m28s 172.31.22.233 ip-172-31-21-230.ec2.internal <none> <none>
app-lab-homolog app-lab-supervisor-56479db977-28hbv 1/1 Running 0 3m28s 172.31.31.106 ip-172-31-21-230.ec2.internal <none> <none>
default inflate-b9d769f59-nm6z2 1/1 Running 0 8m35s 172.31.26.33 ip-172-31-21-230.ec2.internal <none> <none>
kube-system aws-node-n2n6w 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system filebeat-clprj 1/1 Running 0 4m39s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system kube-proxy-zhzdt 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system metricbeat-cbsql 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
lens-metrics node-exporter-nlsbf 1/1 Running 0 4m40s 172.31.28.153 ip-172-31-21-230.ec2.internal <none> <none>
monitoring zabbix-agent-5fqb5 1/1 Running 0 4m39s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 0/1 Pending 0 0s <none> ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 0/1 ContainerCreating 0 0s <none> ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 1/1 Running 0 20s 172.31.30.64 ip-172-31-21-230.ec2.internal <none> <none>This article addresses the solution to the problem that occurred in an EKS cluster in version 1.21, where the use of Dockershim was a viable option. Dockershim served as a bridge between ‘kubelet’ (a Kubernetes component) and the Docker Engine. However, this interface has been discontinued, as Kubernetes has shifted its focus towards runtimes that adhere to the CRI (Container Runtime Interface) standard. This change was made to streamline the integration between Kubernetes and various container runtime implementations, allowing for greater flexibility and compatibility across different container technologies.
Amazon Elastic Kubernetes Service (Amazon EKS) has also ended support for “dockershim” starting with Kubernetes version 1.24. The official Amazon Machine Images (AMI) for version 1.24 and later only include the “containerd” as runtime, while versions prior to 1.24 included both Docker Engine and “containerd,” with Docker Engine as the default runtime.
It is necessary to keep in mind that there are specific Amazon Machine Images (AMIs) for AWS EKS that do not use Dockershim, but rather the “containerd” directly. An example is Bottlerocket, so it is important to be careful during this change, so as not to end up impacting other existing workloads in the same cluster.
Following are some details about the versions of resources used in the environment:
When handling Container Runtime, versions, etc., it is interesting to evaluate whether the chosen version is compatible with the Kubernetes cluster version.
ContainerD
To evaluate the most suitable version of ContainerD, we can use the website below:
https://containerd.io/releases
This site presents a matrix that shows the versions of the “containerd” recommended for a given Kubernetes version. Indicates that any actively supported version of “containerd” may receive bug fixes to resolve issues found in any version of Kubernetes. Recommendation is based on the most extensively tested versions.
If the version is not available in this matrix, you can find it in the release history:
https://github.com/containerd/containerd/releases
For Docker, it is possible to check the changelog, according to the Kubernetes version tag:
https://github.com /kubernetes/kubernetes/tree/v1.21.0/pkg/kubelet/dockershim
We do not have a matrix containing the versions of Dockershim compatible with each version of Kubernetes, however in the case of AWS EKS, we have plenty of details regarding theDockershim deprecation on the page below:
https://docs.aws.amazon.com/eks/latest/userguide/dockershim-deprecation.html
When a pod remains in the ContainerCreating status, it indicates that the container within the pod is struggling to start. This can happen due to various reasons, such as resource constraints, misconfigured settings, or issues with the underlying infrastructure. Let’s dive into the details.
One common cause is insufficient resources—CPU, memory, or storage. Pods may fail to start if they don’t have enough resources allocated. We’ll explore how to adjust resource requests and limits to prevent this issue of Pods stuck in ContainerCreating status with Karpenter.
Another culprit is image pull failures. If the container image specified in your pod’s configuration cannot be pulled from the container registry, the pod won’t start. We’ll discuss strategies to troubleshoot and resolve image-related problems.
Now that we’ve identified potential causes, let’s walk through troubleshooting steps:
To prevent future occurrences, consider the following best practices:
By following these steps and best practices, you can troubleshoot and resolve the dreaded ContainerCreating status. Remember to monitor your pods and nodes continuously to catch issues early. Happy Kubernetes troubleshooting!
Encountered other Kubernetes challenges or have questions about pod provisioning? Explore our comprehensive blog posts and resources for in-depth guidance and troubleshooting tips. Additionally, feel free to reach out to our team of experts for personalized assistance.
*Disclaimer: The information provided in this article is for educational purposes only