DevOps Mind
Pods travados no status ContainerCreating com Karpenter: Como corrigir
O Kubernetes é uma plataforma de orquestração poderosa, mas às vezes os pods ficam presos no status ContainerCreating. Neste artigo, exploraremos os motivos comuns para esse problema e forneceremos soluções práticas para colocar seus pods em funcionamento sem problemas. Se você já enfrentou essa situação frustrante, continue lendo para descobrir como solucionar o problema e resolvê-lo.
Tópicos
Problema – Pods travados no status ContainerCreating com o Karpenter
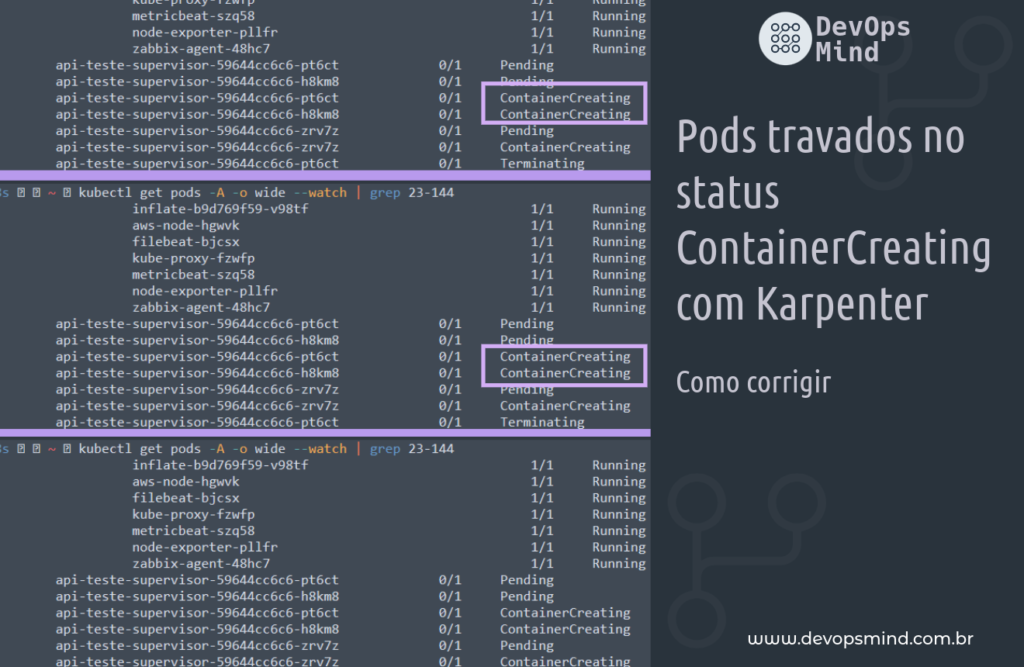
Estamos diante de um problema intrigante e desafiador: a ocorrência recorrente de pods que ficam presos no “ContainerCreating” ao tentar subir em nós provisionados por meio do Karpenter. Esse fenômeno tem impactos significativos na operação normal do Kubernetes, impedindo a implantação eficiente de contêineres e, consequentemente, afetando a agilidade e a confiabilidade do ambiente.
Durante minha jornada de implantação do Karpenter, notei que os pods que usavam a imagem do Docker com base no PHP Alpine estavam travando em ” ContainerCreating”, conforme:
fernando@lab-1487 ~ kubectl get pods -A -o wide --watch | grep 23-144 1|1 ↵ 11105 16:06:39
default inflate-b9d769f59-v98tf 1/1 Running 0 25m 172.31.21.32 ip-172-31-23-144.ec2.internal <none> <none>
kube-system aws-node-hgwvk 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system filebeat-bjcsx 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system kube-proxy-fzwfp 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
kube-system metricbeat-szq58 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
lens-metrics node-exporter-pllfr 1/1 Running 0 33m 172.31.27.199 ip-172-31-23-144.ec2.internal <none> <none>
monitoring zabbix-agent-48hc7 1/1 Running 0 33m 172.31.23.144 ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-h8km8 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-h8km8 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-zrv7z 0/1 Pending 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-zrv7z 0/1 ContainerCreating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 0s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 10s <none> ip-172-31-23-144.ec2.internal <none> <none>
api-cep-homolog api-cep-nbtt-59644cc6c6-pt6ct 0/1 Terminating 0 10s <none> ip-172-31-23-144.ec2.internal <none> <none>
Os pods que tiveram problemas foram aleatórios, muitos pods de outros projetos subiram corretamente.
Vários componentes do cluster Kubernetes foram revisados durante a solução de problemas, como os registros do Pod, Kubelet, Karpenter e outros itens pertinentes.
Nos pods, havia esses registros:
Warning Failed Pod api-cep-nbtt-59644cc6c6-pt6ct spec.containers{api-cep-nbtt} kubelet, ip-172-31-23-144.ec2.internal Error: cannot find
volume "kube-api-access-8lv5h" to mount into container "api-cep-nbtt"Embora o serviço Kubelet tenha essas informações:
[root@ip-172-31-23-144 bin]# systemctl status kubelet.service
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubelet-args.conf, 30-kubelet-extra-args.conf
Active: active (running) since Thu 2023-06-22 18:33:15 UTC; 1h 24min ago
Docs: <https://github.com/kubernetes/kubernetes>
Main PID: 2949 (kubelet)
CGroup: /runtime.slice/kubelet.service
└─2949 /usr/bin/kubelet --cloud-provider aws --config /etc/kubernetes/kubelet/kubelet-config.json --kubeconfig /var/lib/kubelet/kubeconfig --container-runtime remote --container-runtime-endpoint un...
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.402350 2949 kubelet.go:1951] "SyncLoop DELETE" source="api" pods=[api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408804 2949 kubelet.go:1945] "SyncLoop REMOVE" source="api" pods=[api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408869 2949 kubelet.go:2144] "Failed to delete pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc6c6-pt6ct"...d not found"
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034178 2949 kubelet_pods.go:160] "Mount cannot be satisfied for the container, because the volume is missing or the volume mounte...
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034515 2949 kuberuntime_manager.go:864] container &Container{Name:api-cep-nbtt,Image:311635504079.dkr.ecr.u...inerPort:900
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: ],},HTTPGet:nil,TCPSocket:nil,},PreStop:nil,},TerminationMessagePath:/dev/termination-log,ImagePullPolicy:IfNotPresent,SecurityContext:...lObjectRefer
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.037294 2949 pod_workers.go:190] "Error syncing pod, skipping" err="failed to \\"StartContainer\\" for \\"api-cep-nbtt\\" wi...
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.326023 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc...285179c693f}
Jun 22 19:22:32 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.337575 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-nbtt/api-cep-nbtt-59644cc...3ee0fbe11b0}
Jun 22 19:22:33 ip-172-18-23-144.ec2.internal kubelet[2949]: I0622 19:22:33.383158 2949 kubelet_volumes.go:140] "Cleaned up orphaned pod volumes dir" podUID=33966fe3-4ceb-481d-9d57-4586953a8692...692/volumes"
Hint: Some lines were ellipsized, use -l to show in full.
Versão completa:
[root@ip-172-31-23-144 bin]# systemctl status kubelet.service -l
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubelet-args.conf, 30-kubelet-extra-args.conf
Active: active (running) since Thu 2023-06-22 18:33:15 UTC; 1h 28min ago
Docs: <https://github.com/kubernetes/kubernetes>
Main PID: 2949 (kubelet)
CGroup: /runtime.slice/kubelet.service
└─2949 /usr/bin/kubelet --cloud-provider aws --config /etc/kubernetes/kubelet/kubelet-config.json --kubeconfig /var/lib/kubelet/kubeconfig --container-runtime remote --container-runtime-endpoint unix:///run/containerd/containerd.sock --node-ip=172.31.23.144 --pod-infra-container-image=311401143452.dkr.ecr.us-east-1.amazonaws.com/eks/pause:3.5 --v=2 --node-labels=intent=apps,karpenter.sh/capacity-type=spot,karpenter.sh/provisioner-name=default
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.402350 2949 kubelet.go:1951] "SyncLoop DELETE" source="api" pods=[api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408804 2949 kubelet.go:1945] "SyncLoop REMOVE" source="api" pods=[api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct]
Jun 22 19:22:31 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:31.408869 2949 kubelet.go:2144] "Failed to delete pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct" err="pod not found"
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034178 2949 kubelet_pods.go:160] "Mount cannot be satisfied for the container, because the volume is missing or the volume mounter (vol.Mounter) is nil" containerName="api-cep-nbtt" ok=false volumeMounter={Name:kube-api-access-8lv5h ReadOnly:true MountPath:/var/run/secrets/kubernetes.io/serviceaccount SubPath: MountPropagation:<nil> SubPathExpr:}
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.034515 2949 kuberuntime_manager.go:864] container &Container{Name:api-cep-nbtt,Image:311635504079.dkr.ecr.us-east-1.amazonaws.com/api-apphook:supervisor-193,Command:[],Args:[],WorkingDir:,Ports:[]ContainerPort{ContainerPort{Name:9000tcp,HostPort:0,ContainerPort:9000,Protocol:TCP,HostIP:,},},Env:[]EnvVar{},Resources:ResourceRequirements{Limits:ResourceList{cpu: {{500 -3} {<nil>} 500m DecimalSI},memory: {{536870912 0} {<nil>} BinarySI},},Requests:ResourceList{cpu: {{200 -3} {<nil>} 200m DecimalSI},memory: {{268435456 0} {<nil>} BinarySI},},},VolumeMounts:[]VolumeMount{VolumeMount{Name:kube-api-access-8lv5h,ReadOnly:true,MountPath:/var/run/secrets/kubernetes.io/serviceaccount,SubPath:,MountPropagation:nil,SubPathExpr:,},},LivenessProbe:nil,ReadinessProbe:nil,Lifecycle:&Lifecycle{PostStart:&Handler{Exec:&ExecAction{Command:[/bin/bash -c touch /var/www/storage/logs/laravel.log && chgrp -R www-data /var/www/bootstrap/ /var/www/storage/ /var/www/storage/logs/ && chmod -R g+w /var/www/bootstrap/ /var/www/storage/ /var/www/storage/logs/ && tail -f /var/www/storage/logs/laravel.log > /proc/1/fd/2 &
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: ],},HTTPGet:nil,TCPSocket:nil,},PreStop:nil,},TerminationMessagePath:/dev/termination-log,ImagePullPolicy:IfNotPresent,SecurityContext:nil,Stdin:false,StdinOnce:false,TTY:false,EnvFrom:[]EnvFromSource{EnvFromSource{Prefix:,ConfigMapRef:&ConfigMapEnvSource{LocalObjectReference:LocalObjectReference{Name:api-apphook-php,},Optional:nil,},SecretRef:nil,},},TerminationMessagePolicy:File,VolumeDevices:[]VolumeDevice{},StartupProbe:nil,} start failed in pod api-cep-nbtt-59644cc6c6-pt6ct_api-cep-homolog(22966fe3-4ceb-481d-9d57-4586953a8692): CreateContainerConfigError: cannot find volume "kube-api-access-8lv5h" to mount into container "api-cep-nbtt"
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: E0622 19:22:32.037294 2949 pod_workers.go:190] "Error syncing pod, skipping" err="failed to \\"StartContainer\\" for \\"api-cep-nbtt\\" with CreateContainerConfigError: \\"cannot find volume \\\\\\"kube-api-access-8lv5h\\\\\\" to mount into container \\\\\\"api-cep-nbtt\\\\\\"\\"" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-pt6ct" podUID=22966fe3-4ceb-481d-9d57-4586953a8692
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.326023 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-h8km8" event=&{ID:5a5e6258-6d1e-4faa-ac8c-4a0c10670eb6 Type:ContainerStarted Data:9af88fa8f99000720300c1d7f7cab91501db31b5a4ba36d51c9a0285179c693f}
Jun 22 19:22:32 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:32.337575 2949 kubelet.go:1973] "SyncLoop (PLEG): event for pod" pod="api-cep-homolog/api-cep-nbtt-59644cc6c6-zrv7z" event=&{ID:eabe3711-a972-494b-922a-3ad1d5c72936 Type:ContainerStarted Data:f9cdd2dd078343c8f2fa9f4744a14d19d4a24992011c0b31ef33f3ee0fbe11b0}
Jun 22 19:22:33 ip-172-31-23-144.ec2.internal kubelet[2949]: I0622 19:22:33.383158 2949 kubelet_volumes.go:140] "Cleaned up orphaned pod volumes dir" podUID=22966fe3-4ceb-481d-9d57-4586953a8692 path="/var/lib/kubelet/pods/22966fe3-4ceb-481d-9d57-4586953a8692/volumes"
No entanto, a análise dos registros não chegou a nada conclusivo.
Solução
Depois de realizar muitas pesquisas e testes, foi encontrada a solução para evitar erros no contêinercreating do status do pod do kubernetes:
É necessário modificar o tempo de execução do contêiner usado no Karpenter Provisioner.
DE:containerd
PARA:dockerd

Nas configurações do Provisioner no Karpenter, foi necessário ajustar o ContainerRuntime da seguinte forma:
############### ContainerRuntime
kubeletConfiguration :
containerRuntime : dockerdAjustar o provisioner do Karpenter:
kubectl delete -f provisioner_v4.yaml
kubectl apply -f provisioner_v4.yamlNós subindo após o ajuste:
fernando@lab-1487 ~ 11123 17:16:18
kubectl get node --selector=intent=apps -L kubernetes.io/arch -L node.kubernetes.io/instance-type -L karpenter.sh/provisioner-name -L topology.kubernetes.io/zone -L karpenter.sh/capacity-type --watch
NAME STATUS ROLES AGE VERSION ARCH INSTANCE-TYPE PROVISIONER-NAME ZONE CAPACITY-TYPE
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 0s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 2s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Unknown <none> 20s amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 20s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal NotReady <none> 50s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 60s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 78s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 80s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spot
ip-172-31-21-230.ec2.internal Ready <none> 110s v1.21.14-eks-48e63af amd64 c5.large default us-east-1b spotE agora os pods conseguiram subir, todos eles com status em running, como esperado:
fernando@lab-1487 ~ kubectl get pods -A -o wide --watch | grep 21-230 1|SIGINT(2) ↵ 11116 17:20:59
app-lab-homolog app-lab-nginx-574bf47b65-whd9l 1/1 Running 0 3m28s 172.31.22.233 ip-172-31-21-230.ec2.internal <none> <none>
app-lab-homolog app-lab-supervisor-56479db977-28hbv 1/1 Running 0 3m28s 172.31.31.106 ip-172-31-21-230.ec2.internal <none> <none>
default inflate-b9d769f59-nm6z2 1/1 Running 0 8m35s 172.31.26.33 ip-172-31-21-230.ec2.internal <none> <none>
kube-system aws-node-n2n6w 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system filebeat-clprj 1/1 Running 0 4m39s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system kube-proxy-zhzdt 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
kube-system metricbeat-cbsql 1/1 Running 0 4m40s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
lens-metrics node-exporter-nlsbf 1/1 Running 0 4m40s 172.31.28.153 ip-172-31-21-230.ec2.internal <none> <none>
monitoring zabbix-agent-5fqb5 1/1 Running 0 4m39s 172.31.21.230 ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 0/1 Pending 0 0s <none> ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 0/1 ContainerCreating 0 0s <none> ip-172-31-21-230.ec2.internal <none> <none>
api-cep-homolog api-cep-supervisor-59644cc6c6-mdnvg 1/1 Running 0 20s 172.31.30.64 ip-172-31-21-230.ec2.internal <none> <none>Entendendo o problema
Dockershim vs CRI(Container Runtime Interface)
Este artigo aborda a solução para o problema que ocorreu em um cluster EKS na versão 1.21, em que o uso do Dockershim era uma opção viável. O Dockershim servia como uma ponte entre o “kubelet” (um componente do Kubernetes) e o Docker Engine. No entanto, essa interface foi descontinuada, pois o Kubernetes mudou seu foco para tempos de execução que aderem ao padrão CRI (Container Runtime Interface). Essa alteração foi feita para simplificar a integração entre o Kubernetes e várias implementações de tempo de execução de contêineres, permitindo maior flexibilidade e compatibilidade entre diferentes tecnologias de contêineres.
O Amazon Elastic Kubernetes Service (Amazon EKS) também encerrou o suporte ao “dockershim” a partir da versão 1.24 do Kubernetes. As AMIs (Amazon Machine Images) oficiais para a versão 1.24 e posteriores incluem apenas o “containerd” como tempo de execução, enquanto as versões anteriores à 1.24 incluíam o Docker Engine e o “containerd”, com o Docker Engine como tempo de execução padrão.
É necessário ter em mente que existem AMIs (Amazon Machine Images) específicas para o AWS EKS que não usam o Dockershim, mas sim o “containerd” diretamente. Um exemplo é o Bottlerocket, portanto, é importante ter cuidado durante essa alteração para não acabar impactando outras cargas de trabalho existentes no mesmo cluster.
Versões
A seguir, alguns detalhes sobre as versões dos recursos usados no ambiente:
- Kubernetes gerenciado pelo AWS (EKS), versão 1.21.
- Karpenter v0.23.0.
- Container Runtime: docker://20.10.17
- Versão do RUNTIME do contêiner: containerd://1.6.6
- Versão do Kubelet: v1.21.14-eks-48e63af
- Versão do Kube-Proxy: v1.21.14-eks-48e63af
Matriz de versão do Kubernetes
Ao lidar com o Container Runtime, versões etc., é interessante avaliar se a versão escolhida é compatível com a versão do cluster do Kubernetes.
ContainerD
Para avaliar a versão mais adequada do ContainerD, podemos usar o site abaixo:
https://containerd.io/releases
Este site apresenta uma matriz que mostra as versões do “containerd” recomendadas para uma determinada versão do Kubernetes. Indica que qualquer versão do “containerd” com suporte ativo pode receber correções de bugs para resolver problemas encontrados em qualquer versão do Kubernetes. A recomendação é baseada nas versões mais amplamente testadas.
Se a versão não estiver disponível nessa matriz, você poderá encontrá-la no histórico de versões:
https://github.com/containerd/containerd/releases
Dockershim
Para o Docker, é possível verificar o registro de alterações, de acordo com a tag de versão do Kubernetes:
https://github.com /kubernetes/kubernetes/tree/v1.21.0/pkg/kubelet/dockershim
Não temos uma matriz que contenha as versões do Dockershim compatíveis com cada versão do Kubernetes; no entanto, no caso do AWS EKS, temos muitos detalhes sobre a depreciação do Dockershim na página abaixo:
https://docs.aws.amazon.com/eks/latest/userguide/dockershim-deprecation.html
Outras possibilidades
Quando um pod permanece no status ContainerCreating, isso indica que o contêiner dentro do pod está tendo dificuldades para iniciar. Isso pode ocorrer por vários motivos, como restrições de recursos, definições mal configuradas ou problemas com a infraestrutura subjacente. Vamos nos aprofundar nos detalhes.
Resource Constraints
Uma causa comum é a insuficiência de recursos – CPU, memória ou armazenamento. Os pods podem apresentar problemas na subida se não tiverem recursos suficientes alocados. Exploraremos como ajustar as solicitações e os limites de recursos para evitar esse problema de Pods presos no status ContainerCreating com o Karpenter.
Falhas no Image Pull
Outro culpado são as falhas de extração de imagem. Se a imagem do contêiner especificada na configuração do seu pod não puder ser extraída do registro do contêiner, o pod não será iniciado. Discutiremos estratégias para solucionar problemas relacionados à imagem.
Etapas de solução de problemas
Agora que identificamos as possíveis causas, vamos examinar as etapas de solução de problemas:
- Verificar solicitações e limites de recursos: Revise as solicitações e os limites de recursos do seu pod. Ajuste-os conforme necessário para garantir que haja recursos suficientes disponíveis.
- Inspecionar erros de pull de imagem: examine os eventos do pod para identificar quaisquer erros de pull de imagem. Verifique se a imagem existe no registro especificado e se a autenticação (se necessária) está configurada corretamente.
- Analisar os registros do pod: Mergulhe nos logs do pod para descobrir problemas específicos durante a inicialização do contêiner. Procure mensagens de erro relacionadas à inicialização, dependências ou configuração.
- Revisar condições do nó: Verifique a integridade do nó subjacente em que o pod está agendado. As condições do nó, como pressão de disco, pressão de memória ou problemas de rede, podem afetar a criação do pod.
Boas práticas
Para evitar ocorrências futuras, considere as práticas recomendadas a seguir:
- Planejamento de recursos: estime os requisitos de recursos com precisão e defina solicitações e limites apropriados.
- Políticas de extração de imagens: implemente políticas de extração de imagens para evitar novas tentativas e atrasos desnecessários.
- Sondas de integridade: Configure as sondas de prontidão e vivacidade para garantir que os contêineres estejam íntegros antes de servir o tráfego.
- Manutenção de nós: Faça a manutenção regular dos nós para evitar o esgotamento de recursos ou outros problemas.
Conclusão
Seguindo essas etapas e práticas recomendadas, você pode solucionar problemas e resolver o temido status ContainerCreating. Lembre-se de monitorar seus pods e nós continuamente para detectar problemas com antecedência. Boa solução de problemas do Kubernetes!
Material de apoio
- Documentação oficial do Karpenter – https://karpenter.sh/
- Repositório oficial do PHP – https://hub.docker.com/_/php/
- Mais detalhes sobre a mudança para o ContainerD:
https://aws.amazon.com/pt/blogs/containers/all-you-need-to-know-about -moving-to-containerd-on-amazon-eks/ - Detalhes importantes sobre a depreciação do Dockershim e algumas particularidades para cargas de trabalho que estão no AWS EKS:
https://docs.aws.amazon.com/eks/latest/userguide/dockershim-deprecation.html - Perguntas frequentes sobre a depreciação do Dockershim:
https: //kubernetes.io/blog/2020/12/02/dockershim-faq/
Mais informações
Encontrou outros desafios do Kubernetes ou tem dúvidas sobre o provisionamento de pods? Veja nossas outras postagens sobre Kubernetes e obtenha orientações detalhadas e dicas de solução de problemas. Além disso, sinta-se à vontade para entrar em contato com nossa equipe de especialistas para obter assistência personalizada.
*Isenção de responsabilidade: As informações fornecidas neste artigo são apenas para fins educacionais









